Bits from Debian: Statement about the EU Cyber Resilience Act
 Debian Public Statement about the EU Cyber Resilience Act and the Product Liability Directive
The European Union is currently preparing a regulation "on horizontal
cybersecurity requirements for products with digital elements" known as the
Cyber Resilience Act (CRA). It is currently in the final "trilogue" phase of
the legislative process. The act includes a set of essential cybersecurity and
vulnerability handling requirements for manufacturers. It will require products
to be accompanied by information and instructions to the user. Manufacturers
will need to perform risk assessments and produce technical documentation and,
for critical components, have third-party audits conducted. Discovered security
issues will have to be reported to European authorities within 25 hours (1).
The CRA will be followed up by the Product Liability Directive (PLD) which will
introduce compulsory liability for software.
While a lot of these regulations seem reasonable, the Debian project believes
that there are grave problems for Free Software projects attached to them.
Therefore, the Debian project issues the following statement:
Debian Public Statement about the EU Cyber Resilience Act and the Product Liability Directive
The European Union is currently preparing a regulation "on horizontal
cybersecurity requirements for products with digital elements" known as the
Cyber Resilience Act (CRA). It is currently in the final "trilogue" phase of
the legislative process. The act includes a set of essential cybersecurity and
vulnerability handling requirements for manufacturers. It will require products
to be accompanied by information and instructions to the user. Manufacturers
will need to perform risk assessments and produce technical documentation and,
for critical components, have third-party audits conducted. Discovered security
issues will have to be reported to European authorities within 25 hours (1).
The CRA will be followed up by the Product Liability Directive (PLD) which will
introduce compulsory liability for software.
While a lot of these regulations seem reasonable, the Debian project believes
that there are grave problems for Free Software projects attached to them.
Therefore, the Debian project issues the following statement:
- Free Software has always been a gift, freely given to society, to take and to use as seen fit, for whatever purpose. Free Software has proven to be an asset in our digital age and the proposed EU Cyber Resilience Act is going to be detrimental to it. a. As the Debian Social Contract states, our goal is "make the best system we can, so that free works will be widely distributed and used." Imposing requirements such as those proposed in the act makes it legally perilous for others to redistribute our work and endangers our commitment to "provide an integrated system of high-quality materials with no legal restrictions that would prevent such uses of the system". (2) b. Knowing whether software is commercial or not isn't feasible, neither in Debian nor in most free software projects - we don't track people's employment status or history, nor do we check who finances upstream projects (the original projects that we integrate in our operating system). c. If upstream projects stop making available their code for fear of being in the scope of CRA and its financial consequences, system security will actually get worse rather than better. d. Having to get legal advice before giving a gift to society will discourage many developers, especially those without a company or other organisation supporting them.
- Debian is well known for its security track record through practices of responsible disclosure and coordination with upstream developers and other Free Software projects. We aim to live up to the commitment made in the Debian Social Contract: "We will not hide problems." (3) a.The Free Software community has developed a fine-tuned, tried-and-tested system of responsible disclosure in case of security issues which will be overturned by the mandatory reporting to European authorities within 24 hours (Art. 11 CRA). b. Debian spends a lot of volunteering time on security issues, provides quick security updates and works closely together with upstream projects and in coordination with other vendors. To protect its users, Debian regularly participates in limited embargos to coordinate fixes to security issues so that all other major Linux distributions can also have a complete fix when the vulnerability is disclosed. c. Security issue tracking and remediation is intentionally decentralized and distributed. The reporting of security issues to ENISA and the intended propagation to other authorities and national administrations would collect all software vulnerabilities in one place. This greatly increases the risk of leaking information about vulnerabilities to threat actors, representing a threat for all the users around the world, including European citizens. d. Activists use Debian (e.g. through derivatives such as Tails), among other reasons, to protect themselves from authoritarian governments; handing threat actors exploits they can use for oppression is against what Debian stands for. e. Developers and companies will downplay security issues because a "security" issue now comes with legal implications. Less clarity on what is truly a security issue will hurt users by leaving them vulnerable.
- While proprietary software is developed behind closed doors, Free Software development is done in the open, transparent for everyone. To retain parity with proprietary software the open development process needs to be entirely exempt from CRA requirements, just as the development of software in private is. A "making available on the market" can only be considered after development is finished and the software is released.
- Even if only "commercial activities" are in the scope of CRA, the Free Software community - and as a consequence, everybody - will lose a lot of small projects. CRA will force many small enterprises and most probably all self employed developers out of business because they simply cannot fulfill the requirements imposed by CRA. Debian and other Linux distributions depend on their work. If accepted as it is, CRA will undermine not only an established community but also a thriving market. CRA needs an exemption for small businesses and, at the very least, solo-entrepreneurs.
Information about the voting process: Debian uses the Condorcet method for voting. Simplistically, plain Condorcets method can be stated like so : "Consider all possible two-way races between candidates. The Condorcet winner, if there is one, is the one candidate who can beat each other candidate in a two-way race with that candidate." The problem is that in complex elections, there may well be a circular relationship in which A beats B, B beats C, and C beats A. Most of the variations on Condorcet use various means of resolving the tie. Debian's variation is spelled out in the constitution, specifically, A.5(3) Sources: (1) CRA proposals and links & PLD proposals and links (2) Debian Social Contract No. 2, 3, and 4 (3) Debian Constitution
 This post describes how I m using
This post describes how I m using
 This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.
This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.






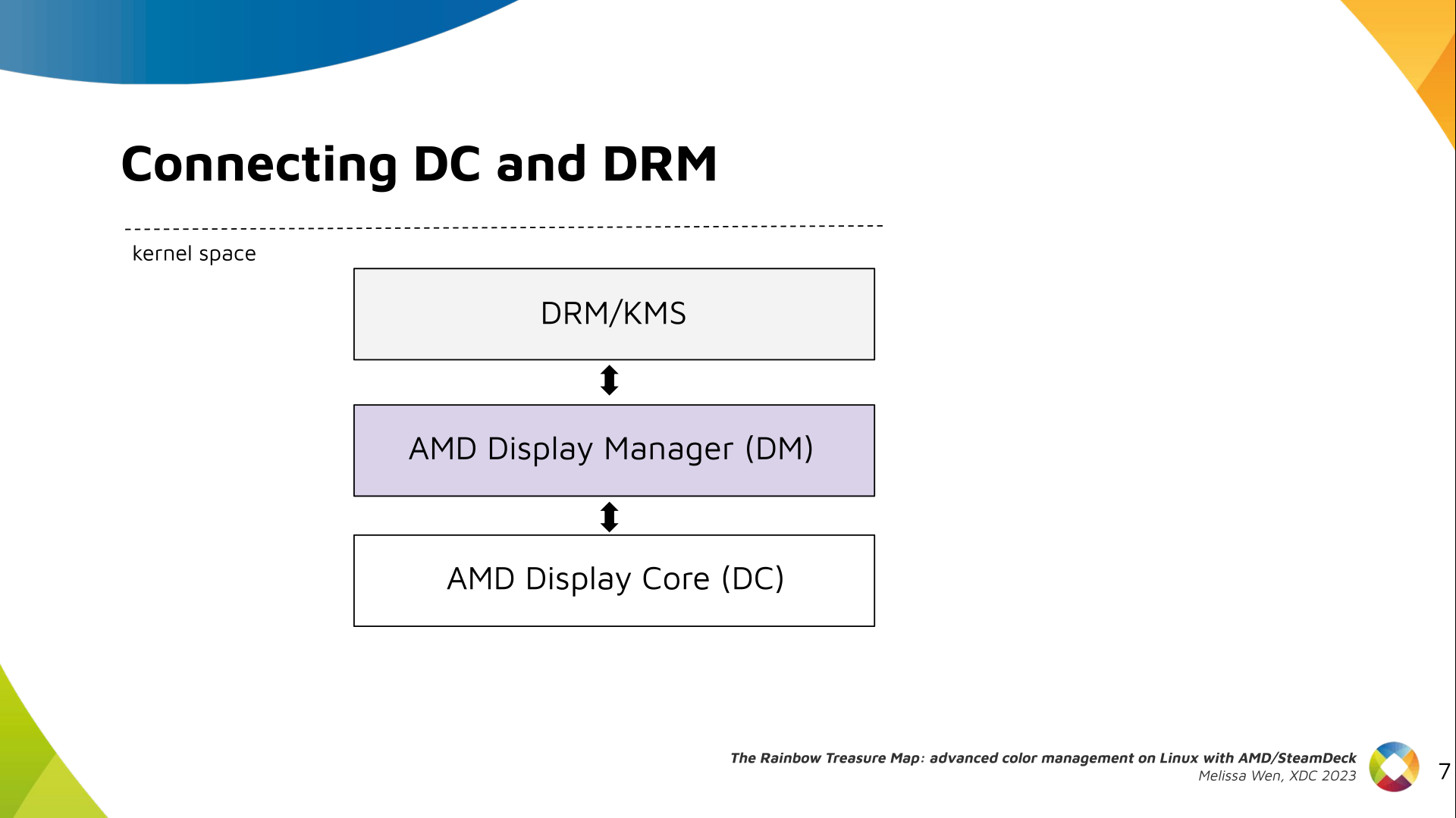
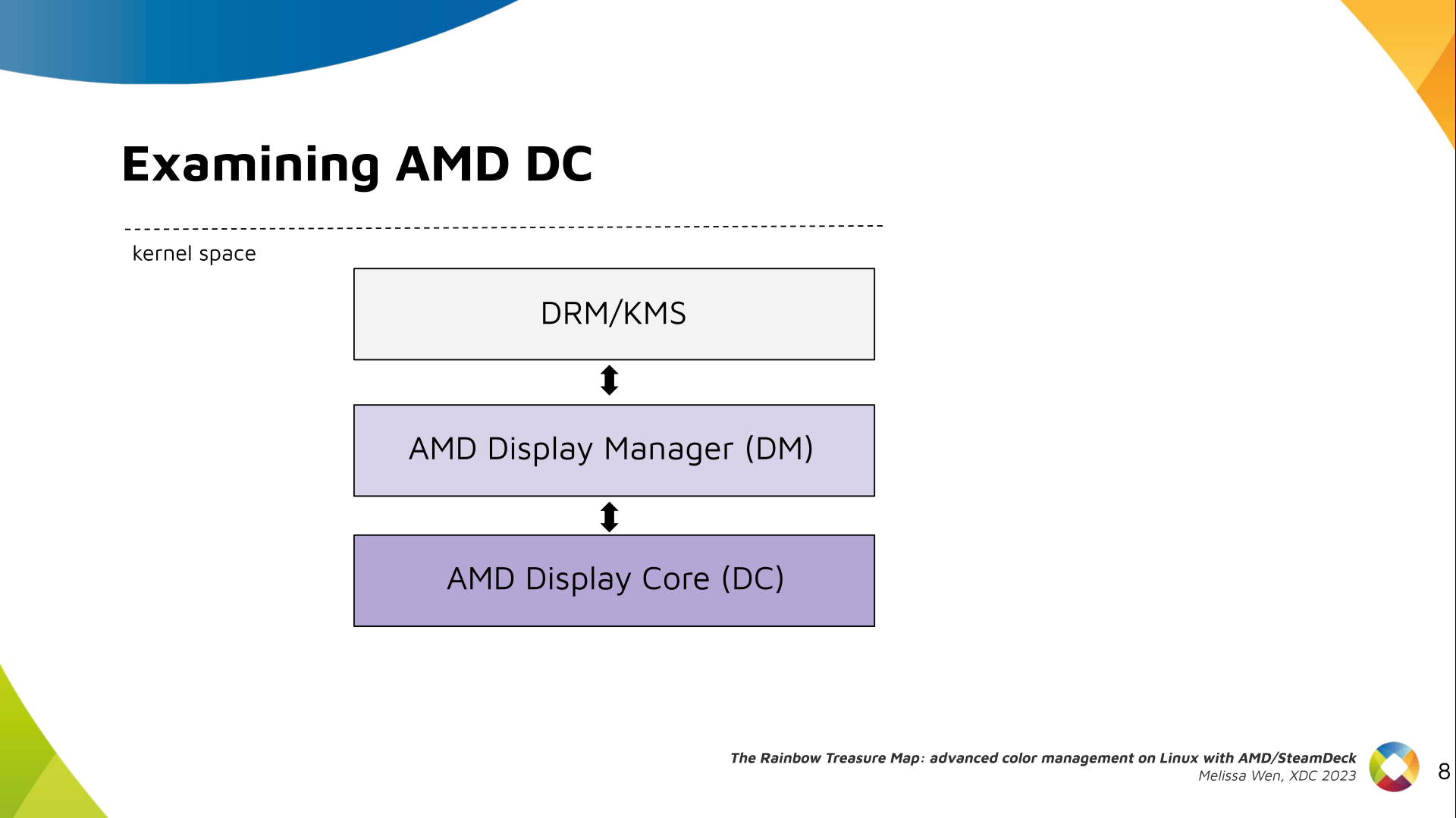
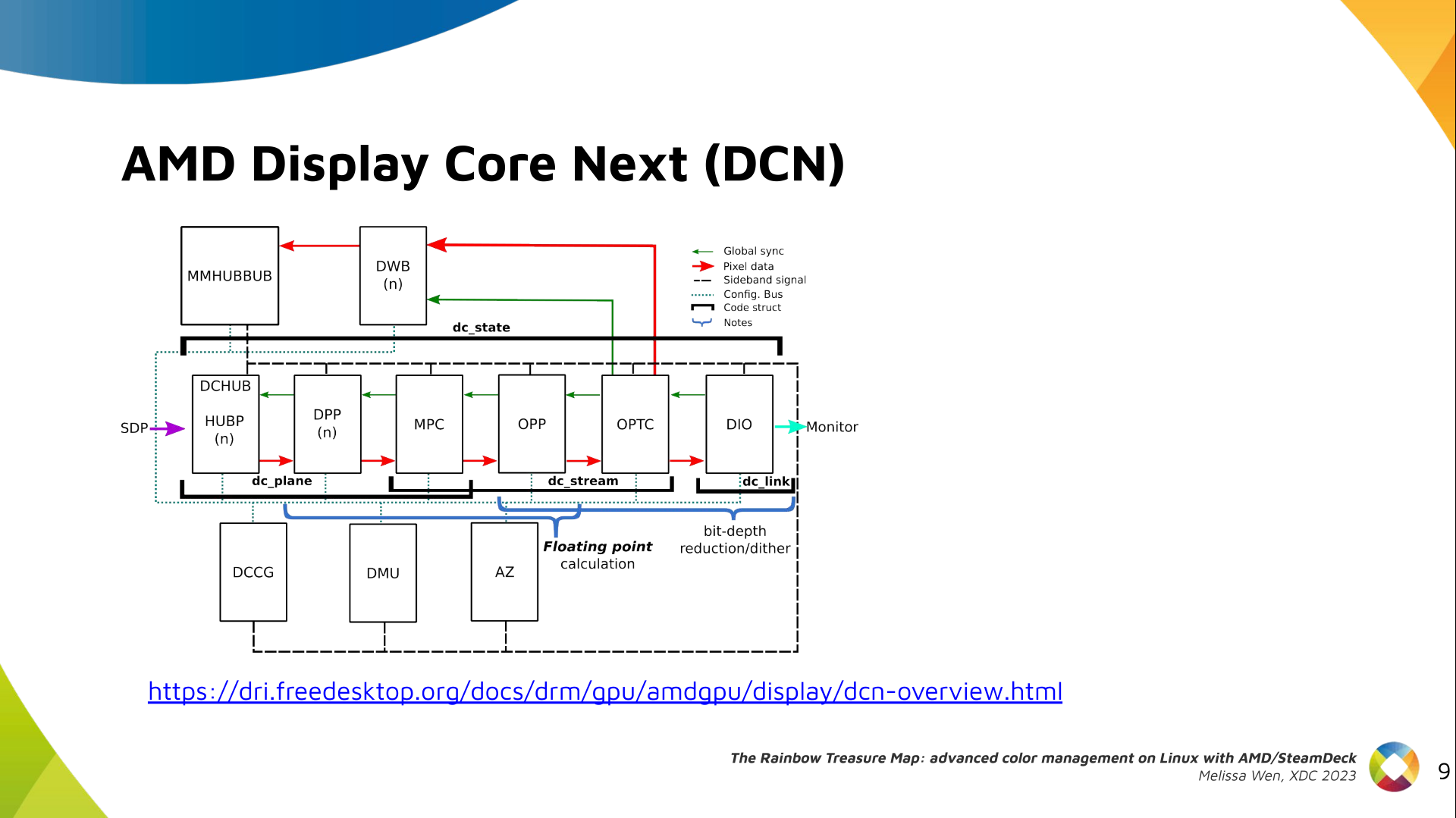


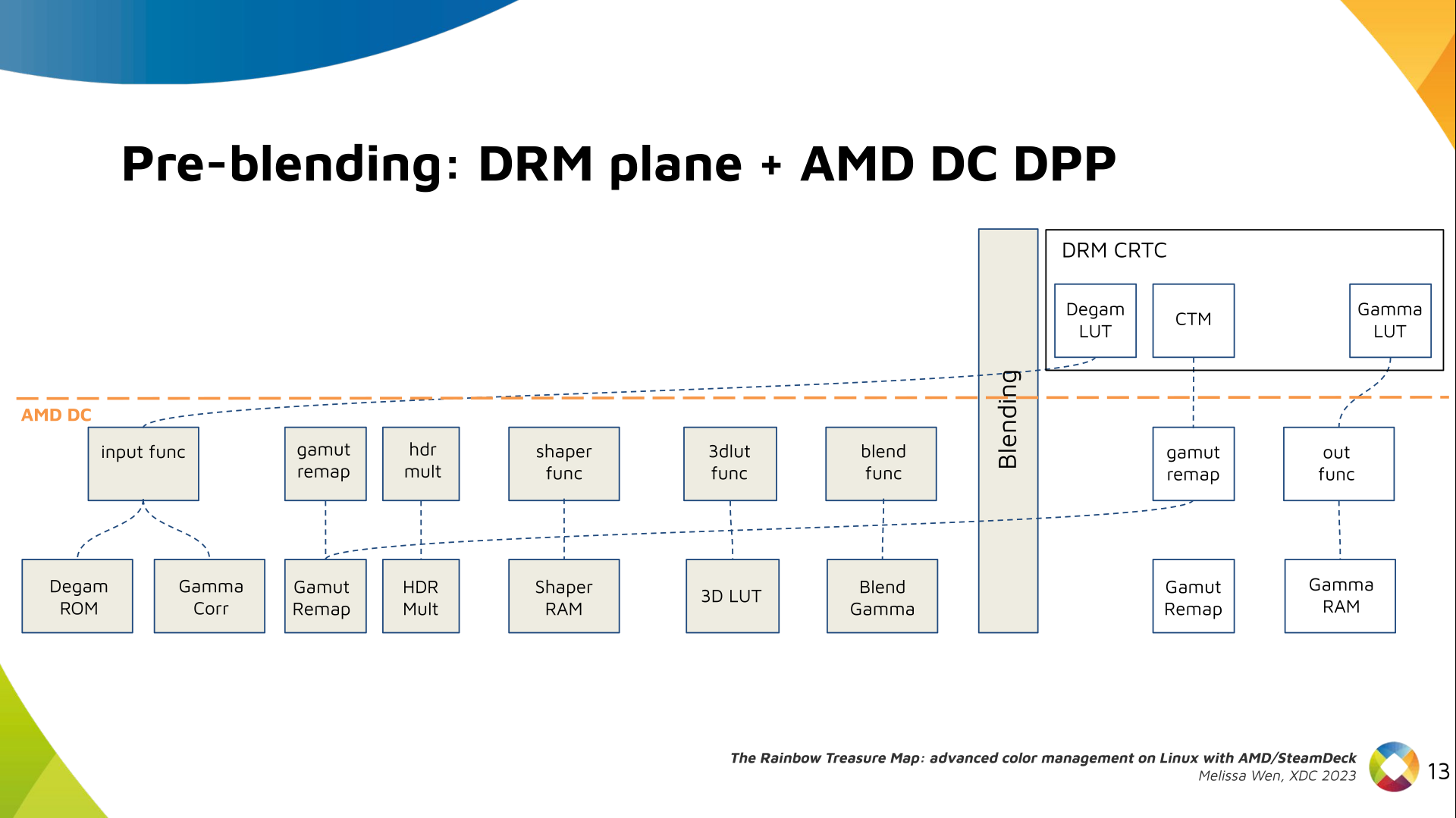
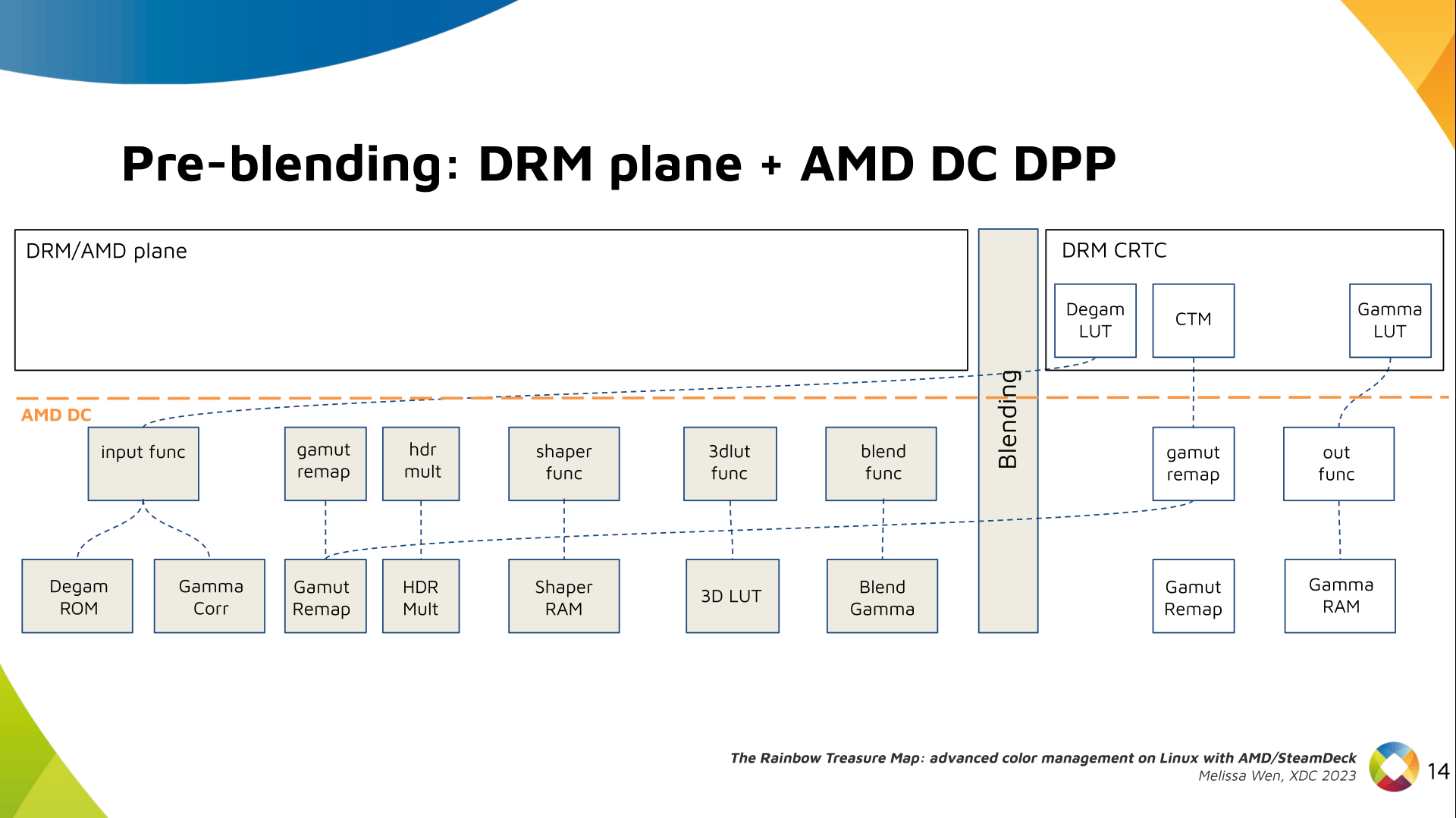
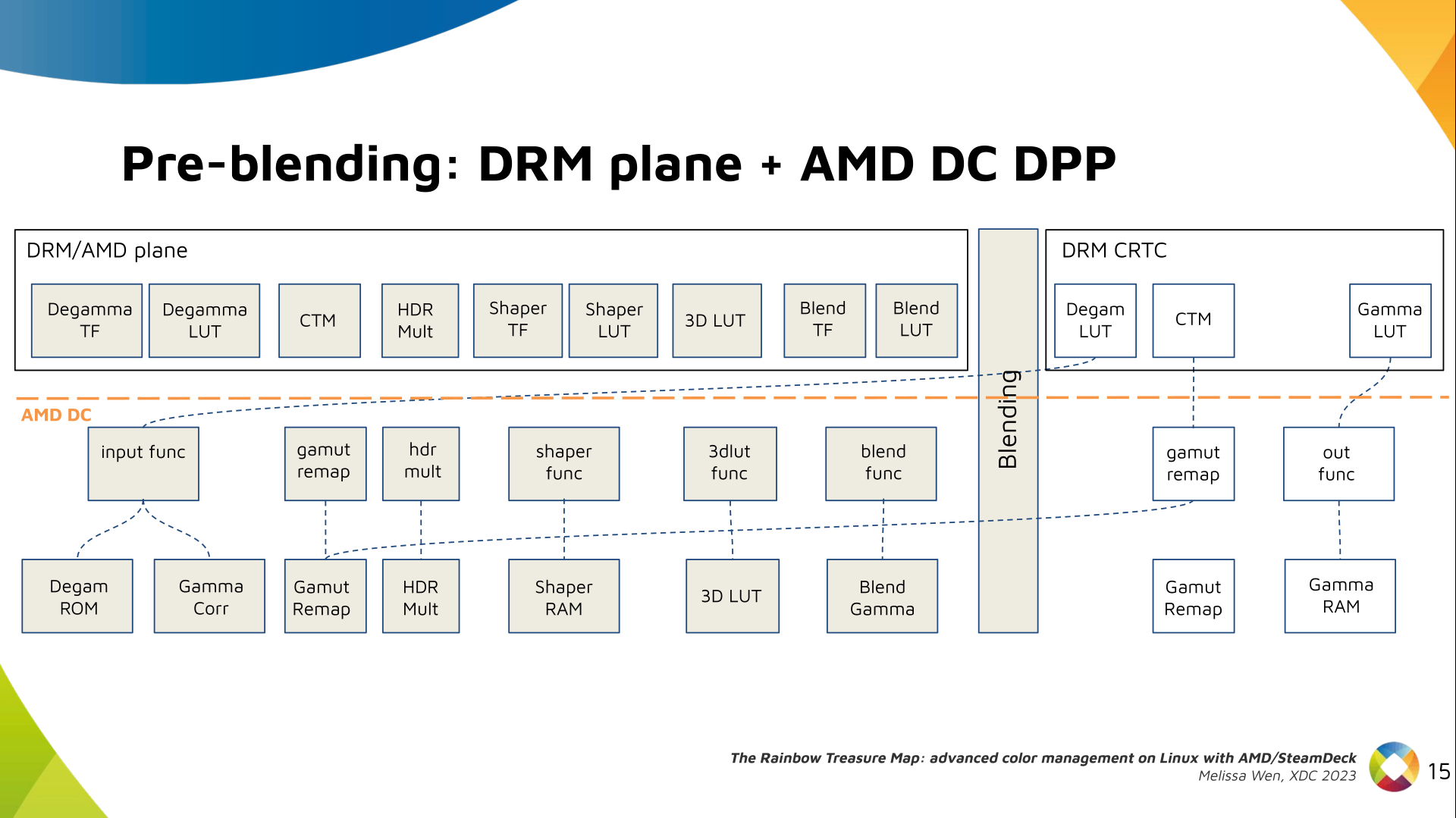
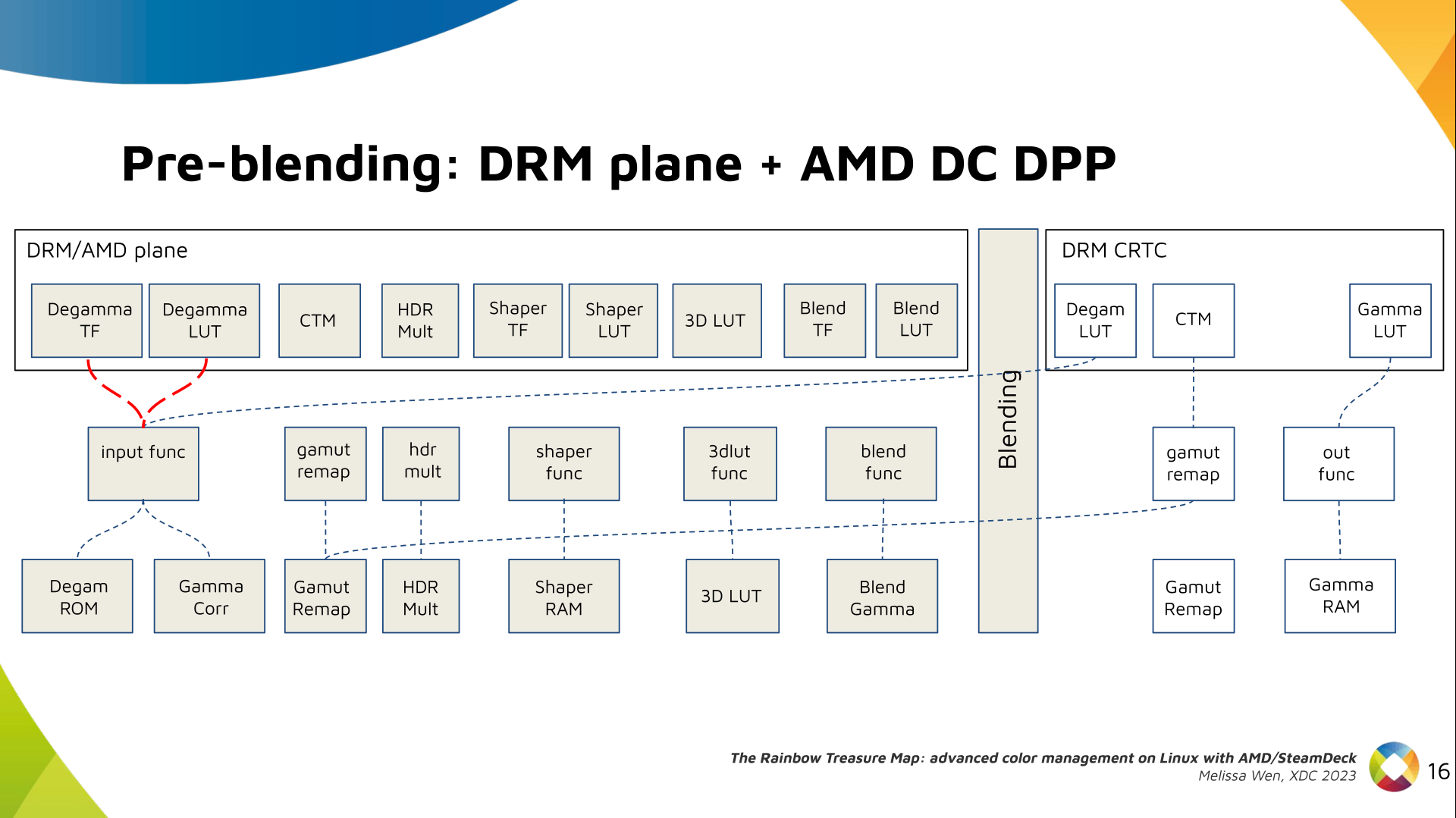

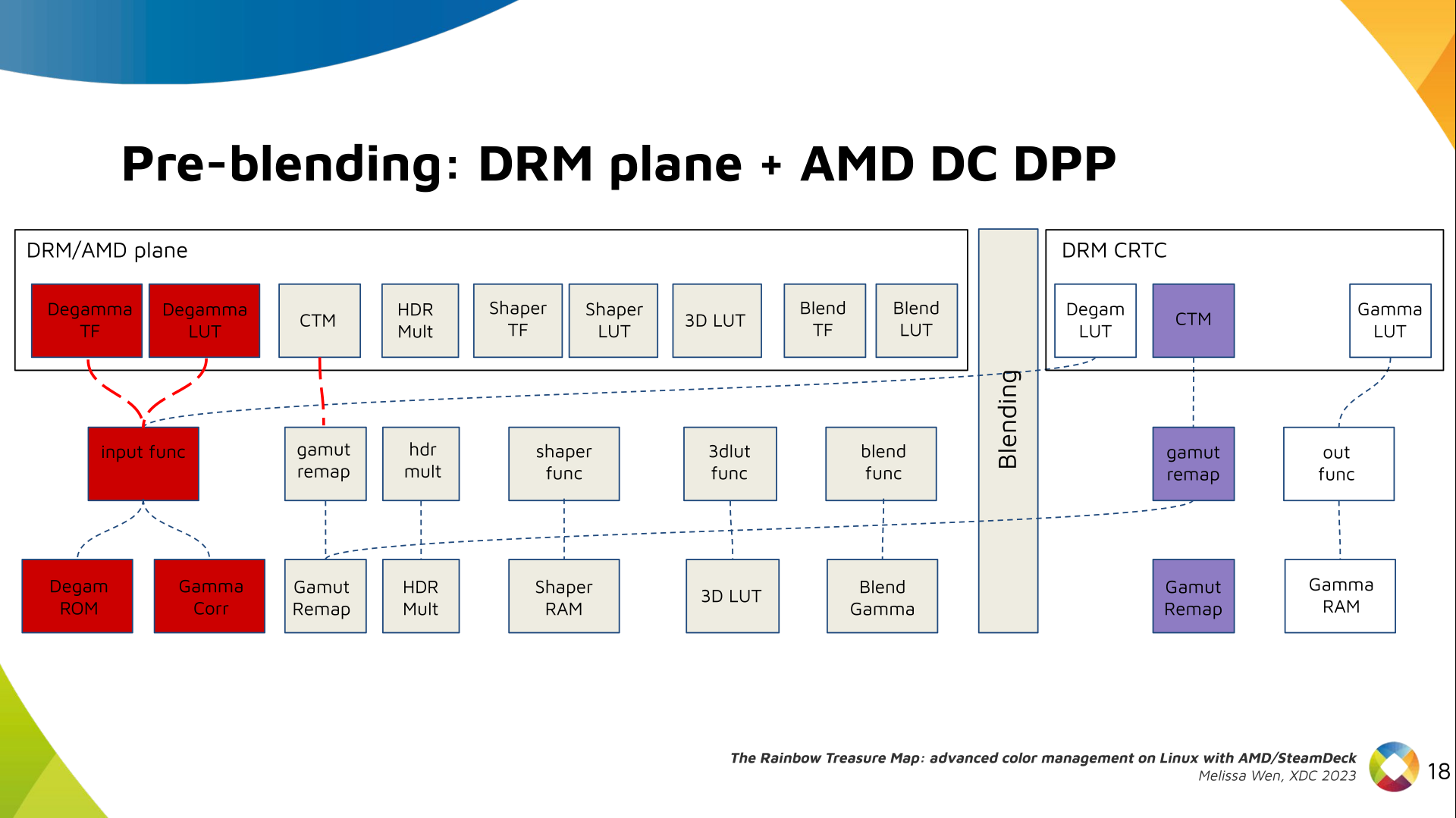

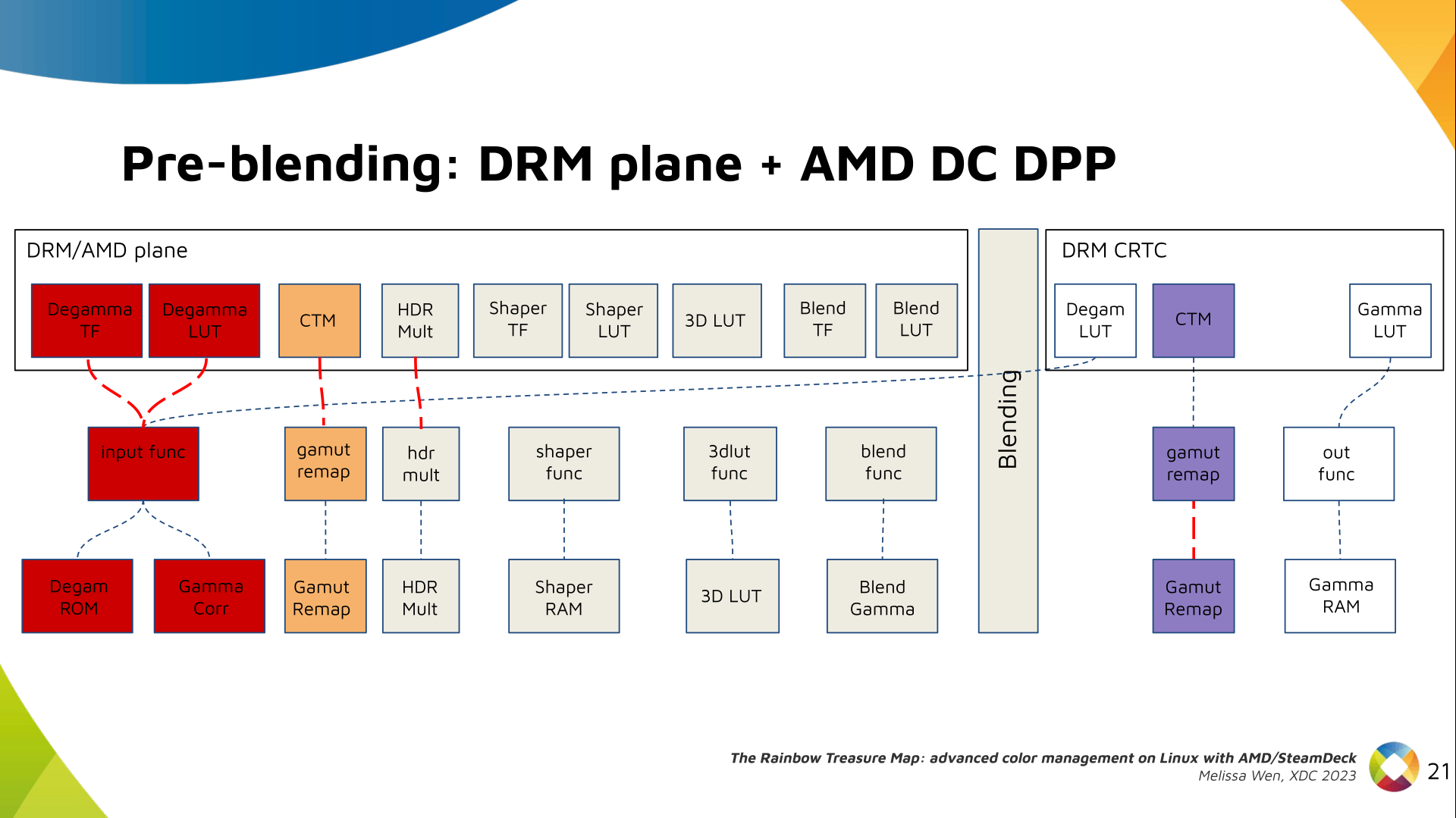

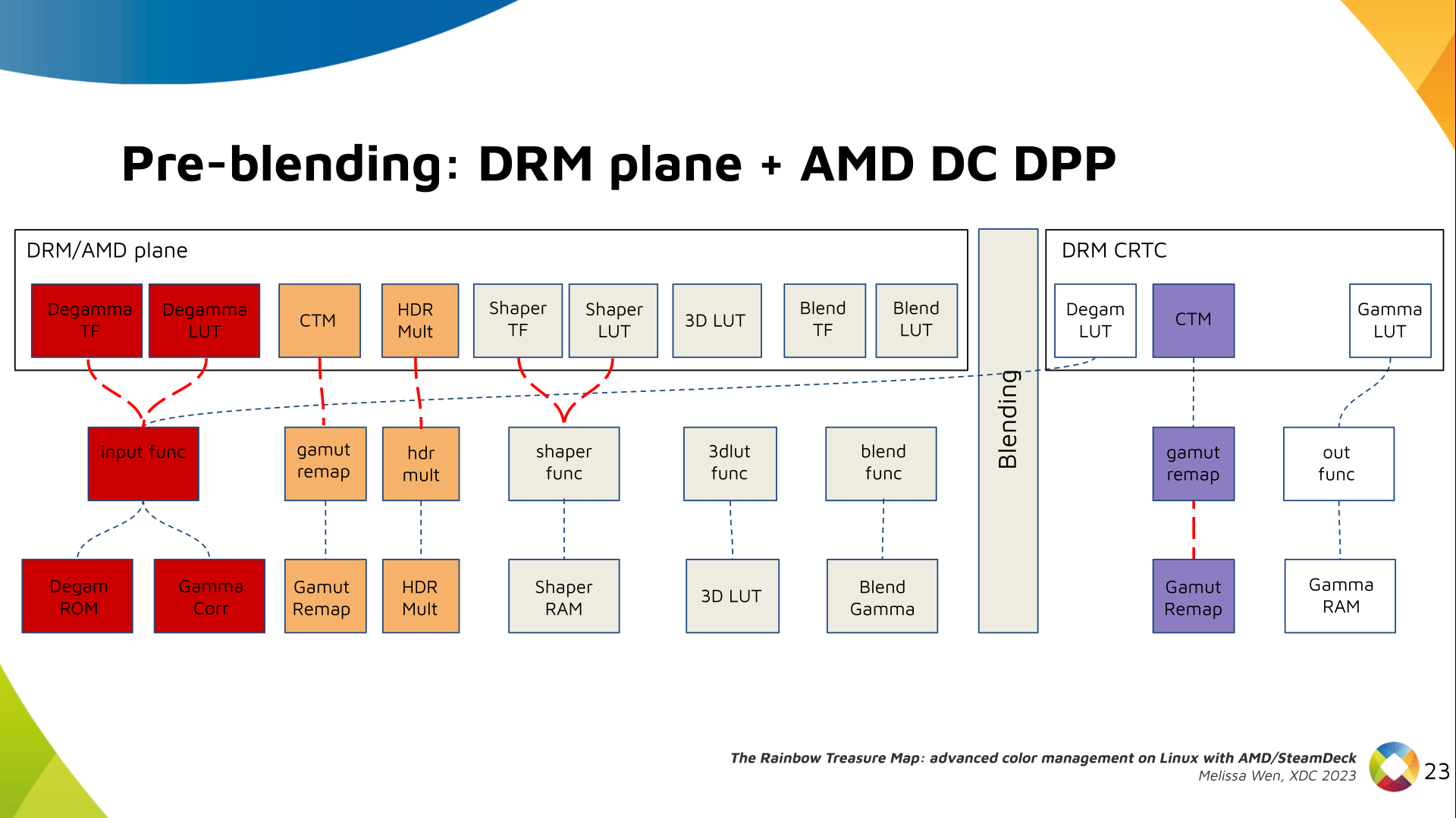

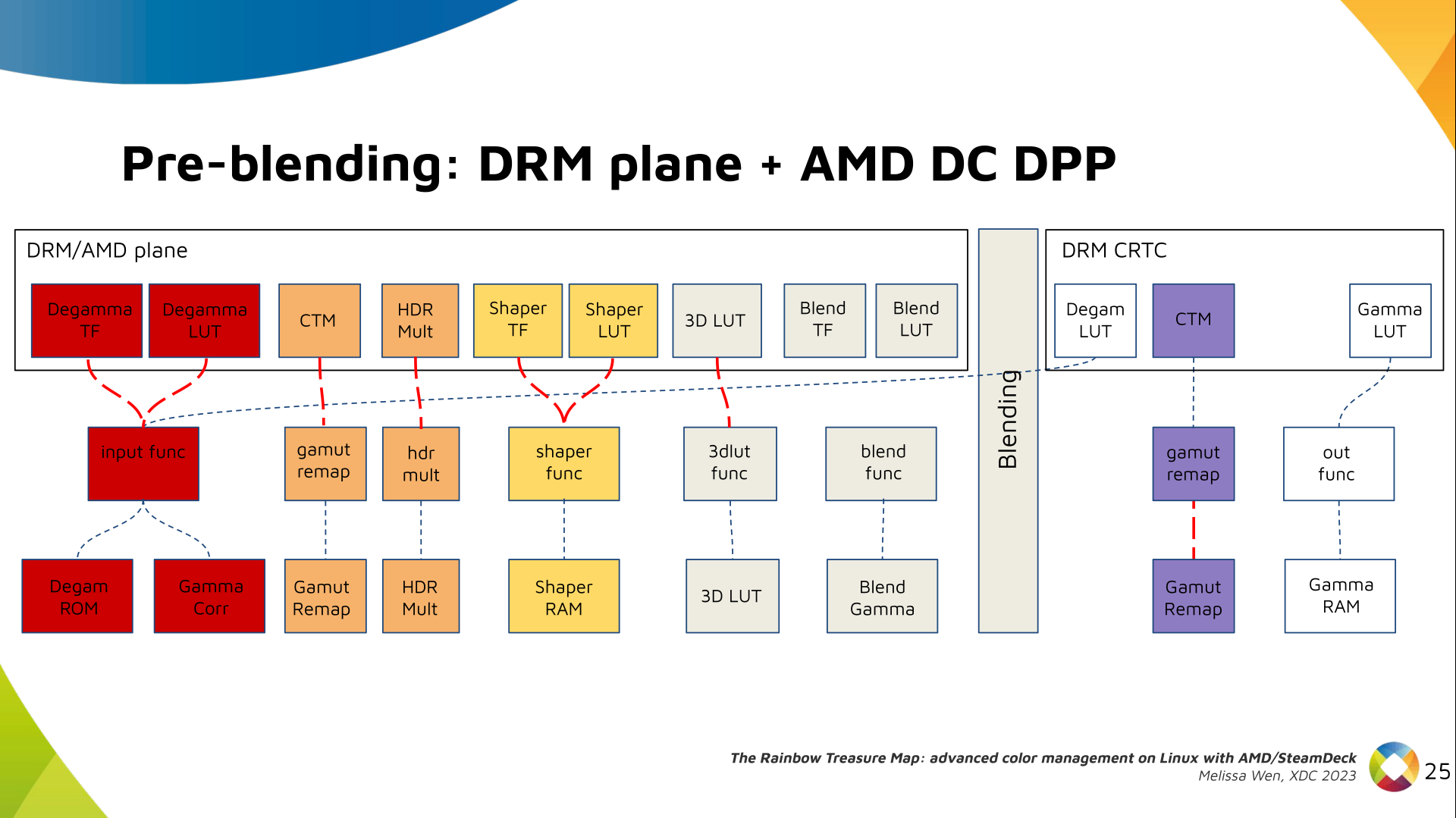

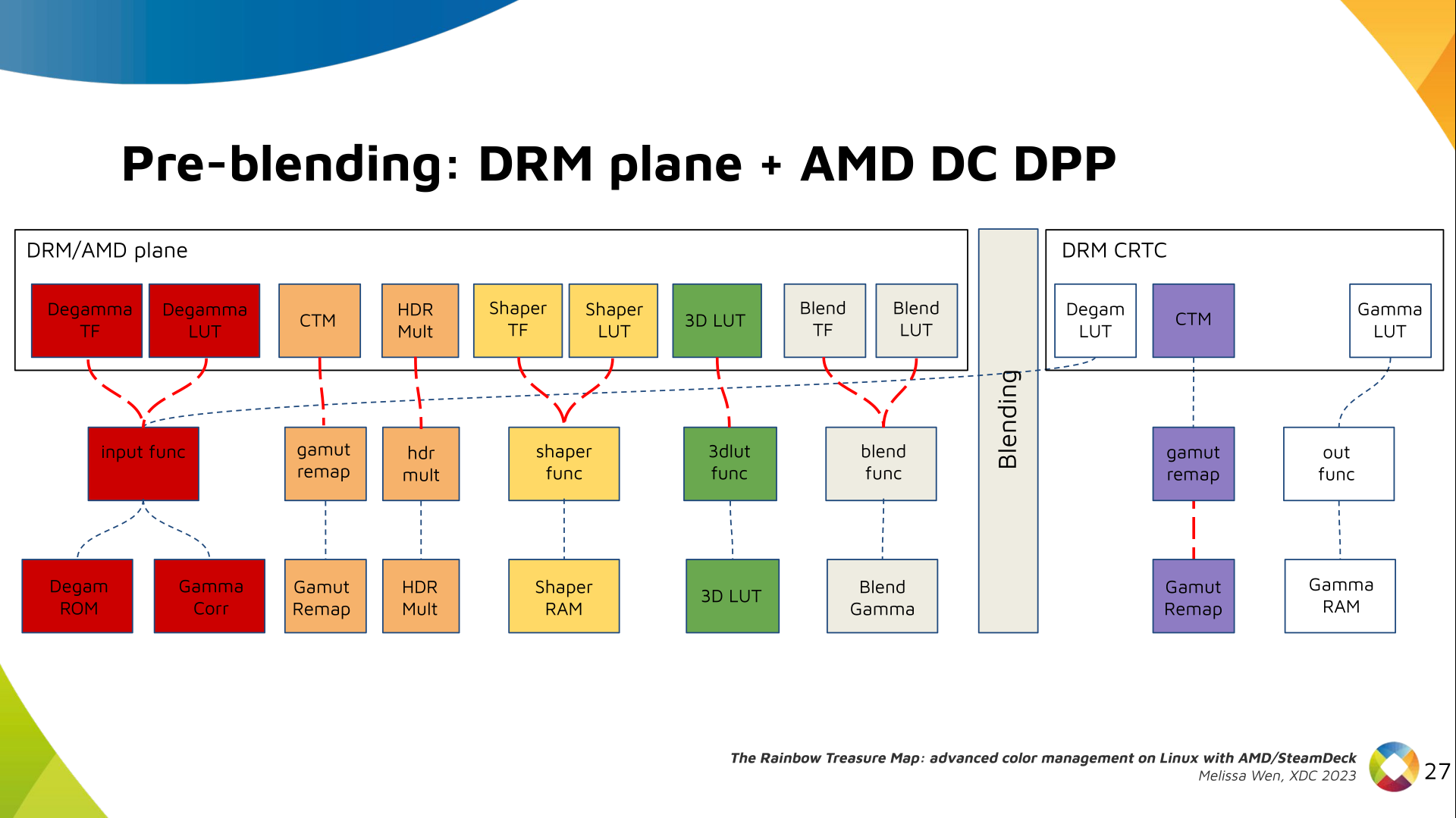

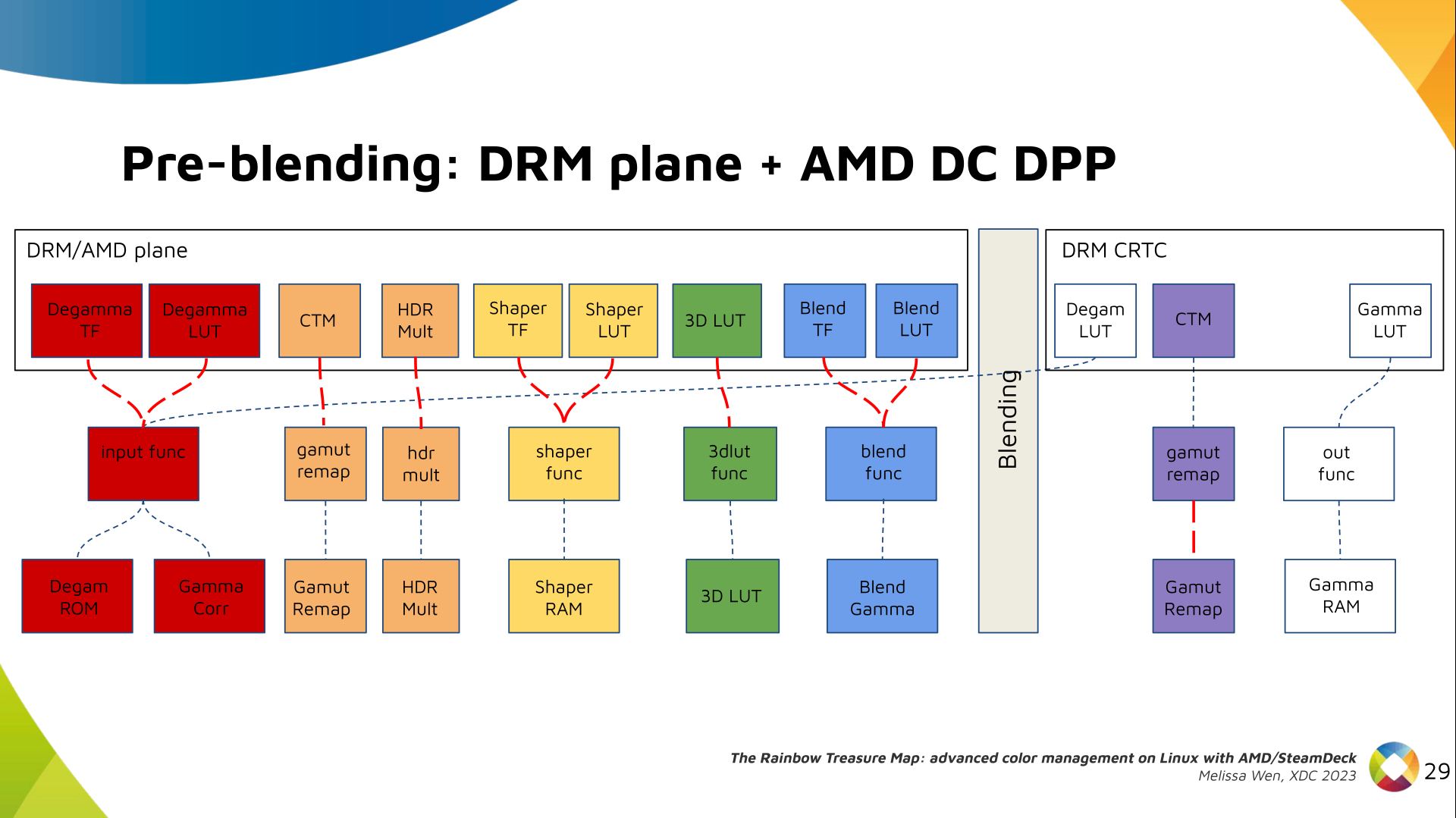
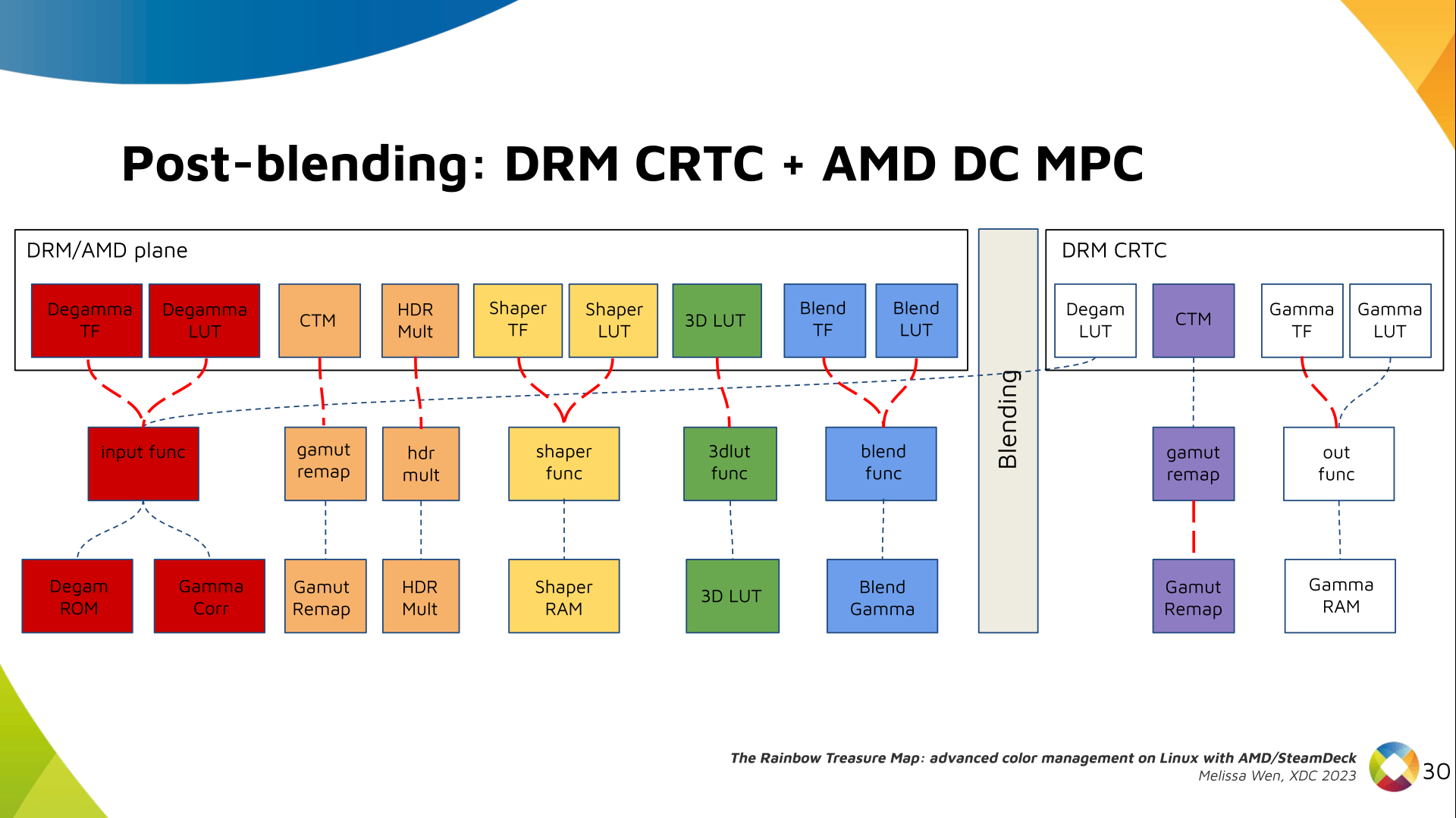

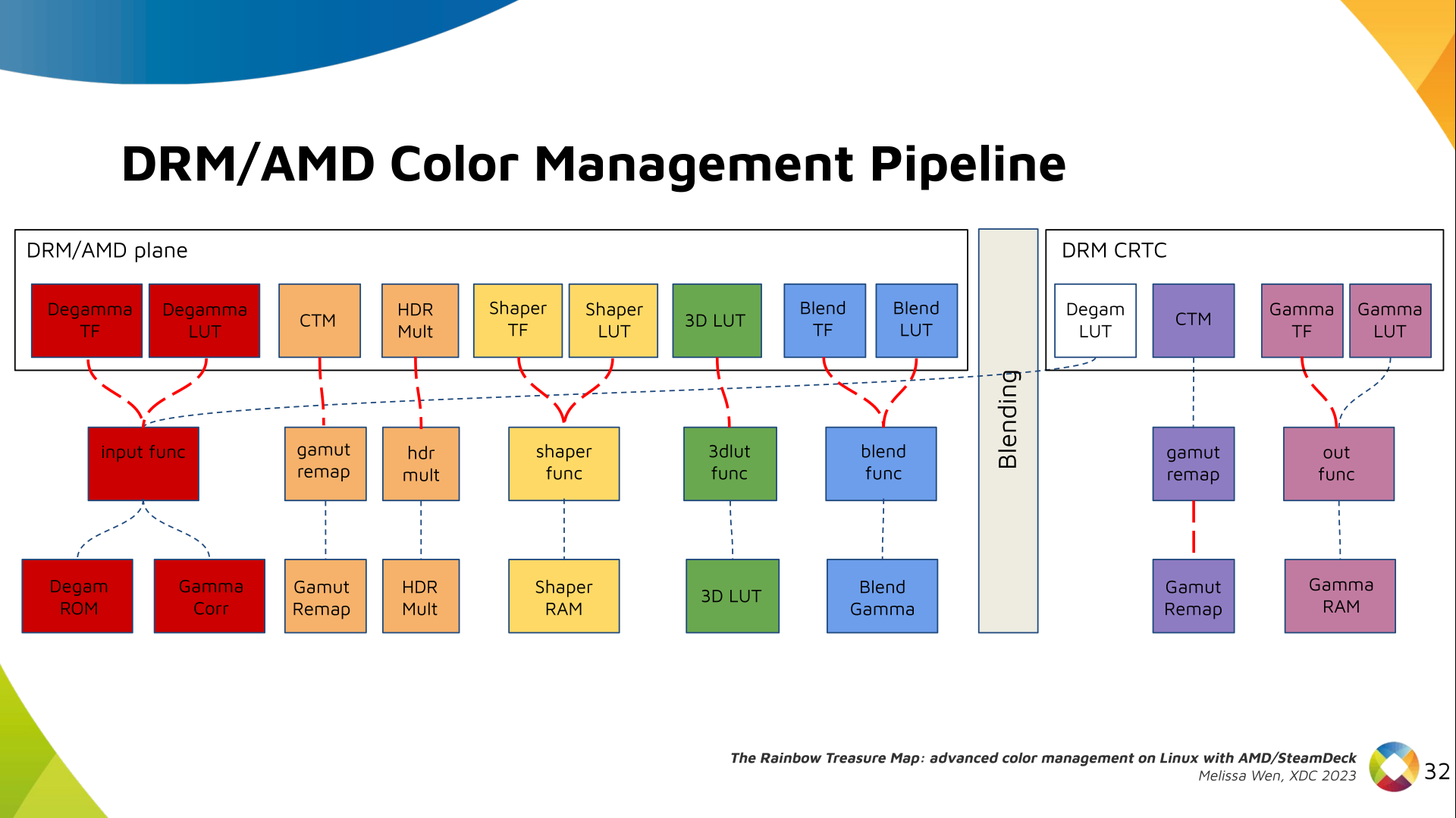
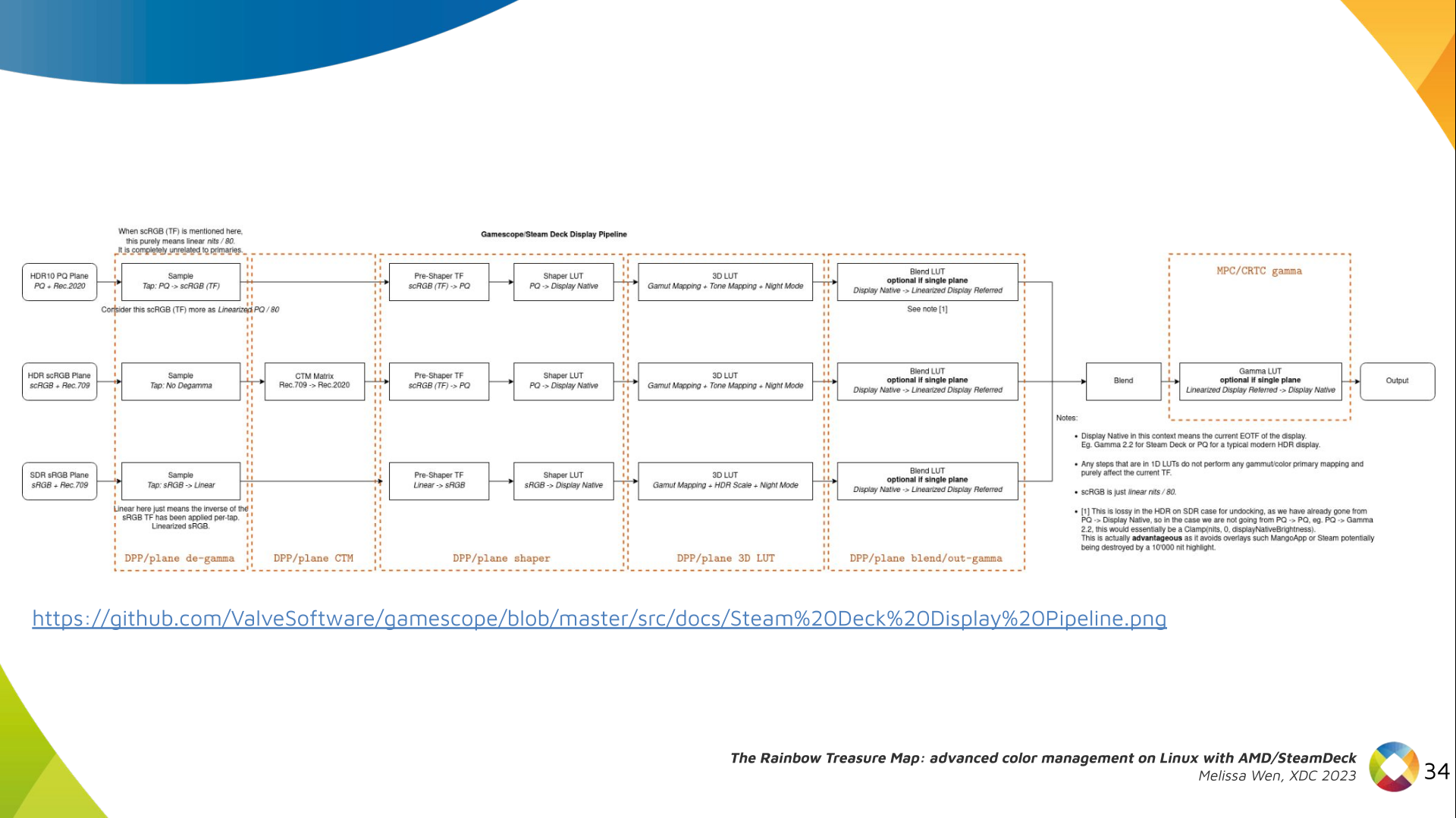


 Delighted to announce a new package that arrived on
Delighted to announce a new package that arrived on  The
The 
 I've been tackling an equivalence problem with rewritten programs in
I've been tackling an equivalence problem with rewritten programs in


 Hello from a snowy Montr al! My life has been pretty busy lately
Hello from a snowy Montr al! My life has been pretty busy lately






{kind=link}